
TL;DR
- Problem: A single ransomware incident can encrypt business data, exfiltrate records, and halt operations for days—putting NJ & NY businesses at regulatory and financial risk.
- Quick answer: Build a layered prevention stack (EDR, MFA, patching, segmentation), implement enterprise-grade backup and disaster recovery with immutable and air-gapped copies, and document an incident response playbook tied to a tested ransomware recovery plan.
- Action now: Run a free IT assessment and gap analysis to map critical systems, set RTO/RPO targets, and validate backups.

Executive summary — why NJ & NY businesses must prioritize ransomware preparedness
Without a clear plan, a ransomware attack can stop billing, lock patient records, and trigger mandatory breach notifications under state and federal rules. Ransomware preparedness nj ny is not just an IT project; it is a business continuity requirement for organizations that operate in New Jersey and New York, especially those subject to healthcare, financial, or regulated-data rules.
"Many local companies underestimate two things: first, that modern ransomware both encrypts files and often exfiltrates data to demand payment; and second, that recovery takes longer than a single restore unless you’ve designed backups and playbooks specifically for ransomware scenarios. For regulated entities, missed notifications and data loss can mean fines and legal exposure under 23 NYCRR Part 500 and HIPAA breach rules. If you have questions or need assistance, feel free to contact us for support."
Practical steps covered in this guide include: defining a ransomware recovery plan, selecting edr siem backup strategies, building air-gapped and immutable backups, prioritizing controls when budgets are tight, and mapping the incident response roles and legal notifications you’ll need. These steps are actionable and tested in real SMB and mid-market environments in NJ and NY.
Backup copies that can be modified are not backups for ransomware; immutable or offline copies are mandatory.
Who this is NOT for
This guide is not aimed at hobby projects, personal devices, or systems containing only public information. It is not a substitute for specialized legal advice for complex cross-border data incidents. If your organization has no networked data and operates entirely offline, many recommendations here will not apply.
Actionable takeaway: If you host regulated data or depend on networked systems for revenue, prioritize a ransomware recovery plan today—start by inventorying critical systems and mapping data flows.
What is ransomware? Quick definition and attack lifecycle (encrypt, exfiltrate, extort)
Ransomware is malware that encrypts files and often exfiltrates data to demand payment. Modern attacks follow a clear lifecycle. Understanding each phase helps you design controls that stop, detect, and recover from attacks.
Lifecycle stages and practical defenses:
- Initial access: Attackers gain entry via phishing, stolen credentials, VPN vulnerabilities, or exposed RDP. Defense: enforce MFA, reduce exposed services, and run phishing-resistant credential policies.
- Lateral movement: After entry, attackers escalate privileges and move across the network. Defense: network segmentation, least privilege, and endpoint detection and response (EDR) that blocks suspicious process behavior.
- Data collection & exfiltration: Adversaries identify valuable data and copy it off-site. Defense: monitor data flows with SIEM, apply DLP for sensitive records, and ensure logging of outbound transfers.
- Encryption and extortion: The attacker encrypts systems and demands payment—often providing a deadline and threats to publish exfiltrated data. Defense: immutable backups, tested restores, and an incident response playbook with legal and PR steps.
Example: A mid-size medical billing firm in northern New Jersey noticed encrypted file extensions across servers. The attacker had used a stolen admin credential obtained through a credential-stuffing campaign. Because the firm lacked immutable backups and had no segmented network, restoration required rebuilding servers from scratch and notifying patients under HIPAA timelines.
Quotable: "Ransomware both encrypts and steals data, turning a recovery exercise into a legal and reputational crisis."
Detecting unusual outbound data transfers early converts a surprise breach into a contained incident.
Actionable takeaway: Treat social engineering and stolen credentials as primary attack vectors; add EDR, enforce MFA, and monitor outbound connections with SIEM to detect exfiltration quickly.
The local/regulatory context — HIPAA, NYDFS, FINRA and how ransomware affects compliance
If you operate in NY or NJ, regulatory obligations change how you respond to ransomware. For example, many NY-regulated entities must follow 23 NYCRR Part 500 (NYDFS), which requires prompt notification to the superintendent for reportable cyber incidents. HIPAA-covered entities must follow HHS breach notification rules, which include a 60-day patient notification window for breaches affecting protected health information, with expedited reporting for large breaches.
How this affects preparedness:
- Notification timelines: Map your incident detection to legal timelines. If an attack hits patient data, HIPAA requires risk assessment and notifications; a slow, untested recovery can cause missed deadlines and penalties.
- Evidence preservation: Regulators expect you to preserve logs and chain-of-custody evidence. Use SIEM to retain relevant logs and document actions during incident response.
- Third-party risk: If you process data for financial services (FINRA-regulated) or healthcare partners, SLA breaches can trigger contractual penalties and mandatory disclosures to partners and regulators.
Example: A New York financial services firm that reported a ransomware incident under 23 NYCRR also had to demonstrate encrypted backups and an incident handling policy; failure to demonstrate reasonable cybersecurity controls increased scrutiny during the investigation.
Quotable: "If a regulated NJ/NY business experiences a reportable cyber incident, NYDFS requires covered entities to notify the superintendent promptly (see 23 NYCRR); HIPAA-covered entities must follow HHS breach notification rules."
Actionable takeaway: Document regulatory notification steps in your ransomware recovery plan and pre-authorize legal and communications leads to act immediately when an incident is declared.
Typical impact on small & mid-size businesses — downtime, fines, reputational harm
A successful ransomware attack damages the bottom line in three clear ways: operational downtime, regulatory and contractual fines, and reputational harm that reduces customer trust. For small and mid-size businesses (SMBs), downtime alone often causes the greatest financial loss.
Concrete impacts and examples:
- Downtime and lost revenue: If critical systems lack RTO/RPO targets, recovery can take days or weeks. Target RTOs/RPOs for critical systems under 24 hours and RPO under 1–4 hours where possible; non-critical systems can aim for RTO under 72 hours.
- Fines and remediation costs: HIPAA notifications and potential NYDFS investigations can add legal and forensics costs. Even without fines, you’ll pay for breach response vendors, forensic analysis, and extra monitoring.
- Reputational harm: Customers may migrate if data is exposed or services are unreliable; insurance rates and vendor terms may worsen after an incident.
Real-world scenario: A small regional clinic in NJ lost 48 hours of appointment scheduling data after a ransomware event. They had working backups but no documented DR runbook; restore took longer than expected because staff didn’t know priorities and the clinic missed the 60-day HIPAA notification window for some patients, triggering additional compliance work.
Actionable takeaway: Quantify the business impact by mapping revenue-critical systems and assigning recovery priorities—this is the first step to building a practical ransomware recovery plan.
Prevention stack — EDR, MFA, patch management, network segmentation, zero-trust
Prevention controls reduce the chance of a successful ransomware attack and limit its scope. A layered stack is necessary: endpoint detection and response (EDR), multi-factor authentication (MFA), timely patch management, network segmentation, and a move toward zero-trust principles. Combine these with SIEM for centralized detection.
How to assemble the stack with examples:
- EDR (endpoint detection and response): Deploy EDR on all endpoints and servers. Configure automated containment rules (e.g., block processes that mass-encrypt files) and ensure the vendor integrates with your SIEM for cross-correlation.
- MFA: Require phishing-resistant MFA for admin access and VPNs. Example threshold: require hardware or app-based MFA for any privileged account and remove permanent admin credentials from daily accounts.
- Patch management: Maintain a patch cadence—apply critical OS and application patches within 7 days for high-risk vulnerabilities and within 30 days for routine updates. Keep an inventory of assets to avoid missed endpoints.
- Network segmentation and least privilege: Segment user workstations from server environment and backups. Block lateral movement by restricting SMB and RDP across VLANs except where explicitly required.
- SIEM and monitoring: Centralize logs and set alerts for events like bulk file renames, unauthorized service account use, or large outbound transfers.
Example implementation: A NJ accounting firm implemented EDR with automated remediation rules, enforced MFA for all administrative logins, and added network micro-segmentation for file servers. When a phishing attempt succeeded on one workstation, EDR contained the process and SIEM alerted the SOC, preventing broader encryption.
edr siem backup strategies: EDR detects and stops suspicious endpoints; SIEM correlates network and user behavior; backups provide recovery. All three together reduce risk and recovery time.
Automated containment in EDR stops the faster “encrypt” stage; immutable backups stop the extortion stage.
Prioritizing controls for resource-constrained organizations
If you have limited budget or staff, prioritize controls that provide the highest risk reduction per dollar. For most small businesses in NJ & NY the recommended order is:
- Implement MFA for all privileged accounts and remote access.
- Deploy EDR on all endpoints and servers, with managed detection if in-house skills are limited.
- Ensure reliable, immutable backups with periodic restore tests.
- Patch critical systems within 7 days and automate patching where possible.
- Establish a minimal incident response playbook that identifies RTO/RPO targets.
Example: A small legal office can reduce risk immediately by enabling MFA across their cloud mail and practice management systems, deploying EDR through a managed service, and outsourcing nightly immutable backups with verification. These measures stop most common attack paths without a full security team.
Actionable takeaway: If you can only do three things this quarter, do MFA, managed EDR, and an immutable backup with a monthly restore test.
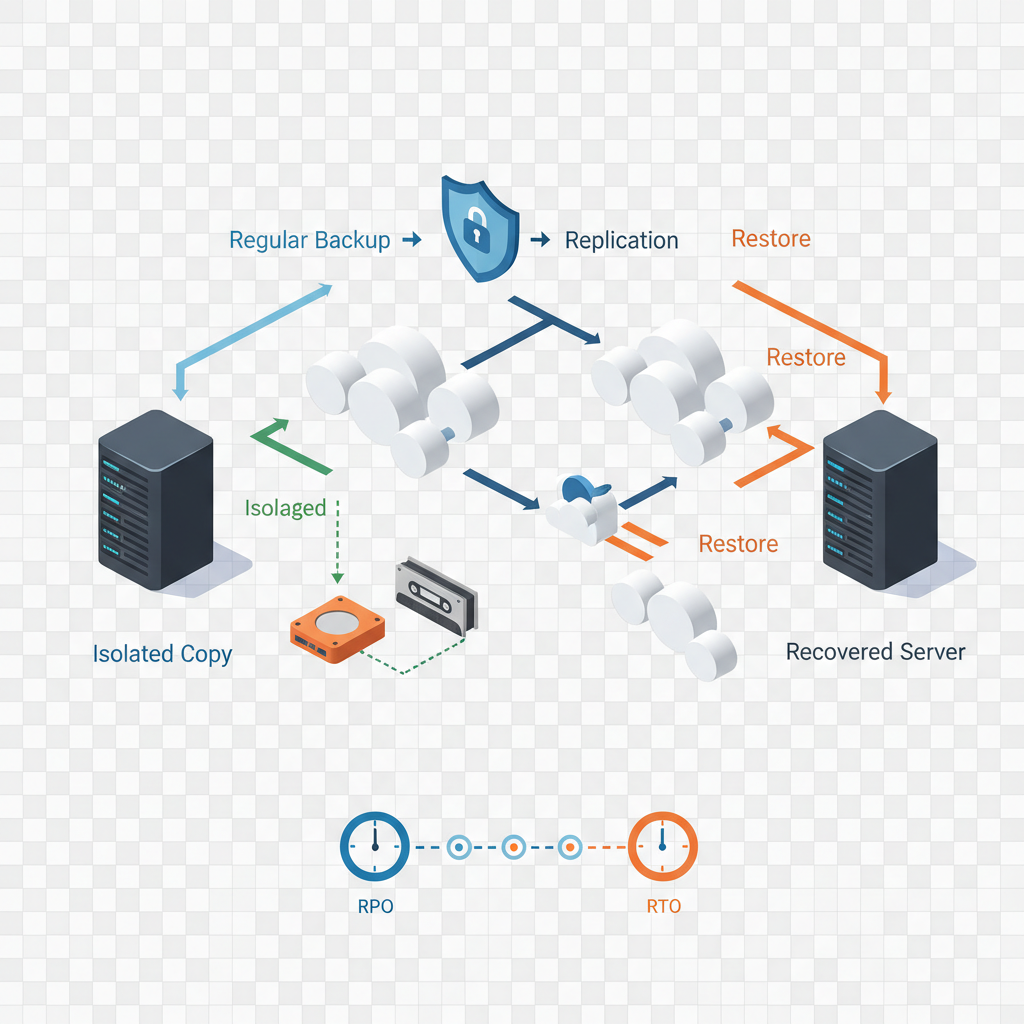
Backup & recovery strategies — air-gapped backups, immutable backups, RPO/RTO planning
Backups are your last line of defense against ransomware. They must be designed for ransomware realities: copies must be immutable or air-gapped, recovery must be tested, and RPO/RTO targets must be defined for each application.
Key backup strategies and examples:
- Immutable backups: Store snapshots that cannot be altered for a retention window. This prevents attackers who reach backup appliances from encrypting or deleting restore points.
- Air-gapped copies: Maintain at least one offline or logically isolated copy (e.g., cloud vault with separate credentials) updated daily or hourly for critical data.
- RPO/RTO planning: For critical systems, target RTO <24 hours and RPO <1–4 hours; for non-critical systems, target RTO <72 hours. Document these targets in your ransomware recovery plan and link them to backup frequency.
- Regular restore tests: Test restores monthly for critical systems and quarterly for others. A backup that hasn’t been restored is a liability, not a safety net.
RTO/RPO planning table:
| System | Business impact | Target RTO | Target RPO |
|---|---|---|---|
| Patient records/EHR | High — clinical operations | <24 hours | <1–4 hours |
| Billing & payments | High — revenue | <24 hours | <4 hours |
| Medium — communications | <24–48 hours | <24 hours | |
| Internal file shares | Low–Medium | <72 hours | Daily |
Example: A NJ construction firm switched to a backup vendor that offers immutable cloud snapshots and retained a weekly air-gapped copy. When a ransomware incident hit two servers, IT restored operations within 22 hours to meet their RTOs.
edr siem backup strategies: Use EDR to limit encryption scope, SIEM to detect exfiltration that might require legal action, and immutable backups to ensure clean recovery points.
Define RTO and RPO for each app in writing; treat those numbers as non-negotiable recovery targets.
Actionable checklist (backups):
- Implement immutable snapshots for all file servers.
- Keep at least one air-gapped copy off-network.
- Document RTO/RPO per system and test restores monthly for top-priority apps.
- Log and retain backup access records in your SIEM.
Cost/benefit: paying ransom vs. restore from backups (decision framework)
Deciding whether to pay a ransom revolves around three factors: likelihood of full recovery without payment, cost and time to restore, and legal/regulatory implications of paying. A simple decision framework helps executives act quickly when under pressure.
Decision framework (example rules):
- If immutable backups exist and restores can meet RTO <24 hours for critical systems, do not pay the ransom; restore from backups.
- If backups are incomplete and restoration will exceed 72 hours, evaluate ransom payment only after consulting legal counsel and incident response experts; consider reputational and regulatory consequences.
- Always assume exfiltration occurred; paying a ransom does not guarantee deletion of stolen data or prevent publication.
Example: A small manufacturer faced a ransom demand but had current air-gapped backups; the CISO authorized a restore and refused payment, recovering operations within 30 hours and avoiding payment and potential future extortion.
Actionable takeaway: Build a decision matrix into your ransomware recovery plan before an incident—identify who can authorize payment, who will lead restores, and how regulators will be notified.
Incident response planning — roles, playbooks, communication & legal steps
An incident response plan makes a chaotic event manageable. A ransomware recovery plan should name roles, define escalation criteria, and include playbooks for containment, eradication, and recovery. Legal and communications steps must be pre-arranged to meet regulatory timelines.
Critical components of a playbook:
- Roles & responsibilities: Assign an incident commander, IT lead, legal counsel, PR lead, and a liaison for regulators and partners. Ensure backups of contact details and alternate communication channels (e.g., out-of-band phone list).
- Containment steps: Isolate affected hosts, revoke compromised credentials, and block known malicious IPs on the firewall. Use EDR to contain and collect forensic artifacts.
- Evidence collection: Preserve logs, capture memory images if appropriate, and document each step to maintain chain-of-custody for regulators or insurers.
- Communication plan: Pre-draft holding statements for customers, partners, and regulators. Identify when to escalate public statements and whom to notify under statutes like 23 NYCRR and HIPAA.
- Third-party coordination: Pre-contract with a forensics provider and legal counsel experienced in cyber incidents to speed response.
Example playbook excerpt: Within 15 minutes of detection, the incident commander declares an incident, isolates the infected VLAN, revokes service accounts used in the compromise, and notifies legal and PR. Forensic snapshots are taken within the first hour and sent to the retained incident responder for analysis.
Quotable: "An incident playbook that names people and steps reduces recovery time by turning decisions made under pressure into practiced procedures."
Actionable takeaway: Create an incident response runbook with step-by-step containment and recovery tasks and run tabletop exercises every six months.
Working with an MSP/MSSP — what services to expect, SLA considerations, senior-engineer support
Working with a managed provider is the pragmatic way many NJ & NY organizations get 24/7 monitoring and senior-engineer-led support. When evaluating MSP/MSSP arrangements, expect services that cover managed EDR, SIEM monitoring, enterprise-grade backup/disaster recovery, and a defined incident response escalation path.
What to expect from a provider:
- 24/7 monitoring: Continuous SIEM and SOC coverage with documented alerting thresholds and escalation.
- Senior-engineer-led support: Access to experienced engineers for incident handling and forensics rather than only junior technicians.
- Backup & disaster recovery: Enterprise-grade backup/disaster recovery offering with immutable and air-gapped options and periodic restore validation.
- SLA considerations: SLAs should cover detection-to-response times, incident escalation windows, and backup verification windows—not just ticket response times.
Example expectations: An MSP should provide a documented SLA that defines a SOC alert-to-investigation handoff within 30 minutes for high-severity incidents, senior-engineer engagement for declared incidents, and quarterly restoration tests for critical systems.
How Eighty Seven Solutions helps: Eighty Seven Solutions’ Services include managed monitoring and senior-engineer-led support combined with enterprise-grade backup/disaster recovery that aligns with RTO/RPO planning for NJ & NY businesses. For teams that lack in-house security expertise, managed ransomware protection through a vetted MSP/MSSP reduces risk while enabling fast recovery.
Actionable takeaway: When selecting an MSP/MSSP, require documented restore test results, clear escalation paths to senior engineers, and SLAs that match your RTO/RPO targets.
Checklist & templates — a downloadable preparedness checklist and sample DR runbook
Below are reusable artifacts you can copy into your own preparedness plan: a readiness checklist, a sample incident runbook table, and a recovery decision matrix. Use these to accelerate your ransomware recovery plan and to run tabletop exercises.
Readiness checklist (copyable):
- Inventory all systems and classify by business impact.
- Document RTO and RPO for each system and application.
- Deploy EDR on all endpoints and integrate alerts into SIEM.
- Enable MFA for all admin and remote access accounts.
- Implement immutable backups and at least one air-gapped copy.
- Schedule monthly restore tests for critical systems.
- Create an incident response playbook with named roles.
- Retain legal and forensic partners under a pre-incident contract.
- Run tabletop exercises every six months and document lessons learned.
Sample DR runbook (simplified table):
| Step | Action | Owner | Target timeframe |
|---|---|---|---|
| Declaration | Incident commander declares incident and notifies contacts | Incident commander | <15 minutes |
| Containment | Isolate affected VLANs and revoke compromised accounts | IT lead | <30 minutes |
| Forensics | Collect logs and images, preserve evidence | Forensics partner | <2 hours |
| Recovery | Restore from immutable backup according to RTO priorities | Recovery lead | As per RTO |
| Notification | Notify regulators, partners, and customers per legal checklist | Legal/Compliance | As required |
Decision matrix (sample guidance):
- If backups meet RTO <24h for critical systems → Restore, do not pay.
- If backups incomplete and estimated downtime >72h → Convene executive decision panel and legal counsel to evaluate payment vs. rebuild.
- Always assume exfiltration; proceed with notifications required by regulation.
Actionable takeaway: Copy these templates into your internal documentation, run one tabletop this quarter, and validate one backup restore before year-end.
Next steps & CTA — free IT assessment, gap analysis, how Eighty Seven Solutions helps
Start with three simple steps: inventory, test, and partner. Inventory your most critical systems and map RTO/RPO; run a restore test this month; and engage a managed provider to fill skill gaps.
Eighty Seven Solutions offers a range of services that include 24/7 monitoring, senior-engineer-led support, and enterprise-grade backup/disaster recovery tailored for NJ & NY businesses. A free IT assessment and gap analysis identifies immediate weaknesses in your prevention stack and backup architecture, providing a prioritized roadmap to a complete ransomware recovery plan.
Quotable: "A tested ransomware recovery plan reduces decision-making time during an incident to minutes rather than days."
Actionable CTA: Get a free IT assessment and gap analysis to produce a prioritized ransomware recovery plan and schedule your first restore test.
FAQ
What is ransomware preparedness & recovery? Ransomware preparedness & recovery is the set of policies, technical controls, backup architectures, and playbooks designed to prevent ransomware, detect and contain attacks quickly, and restore operations with defined RTO/RPO targets in NJ and NY business environments.
How does ransomware preparedness & recovery work? It combines a layered prevention stack (EDR, MFA, patching, segmentation), immutable and air-gapped backups with tested restores, and an incident response plan that names roles, legal notifications, and communication steps to meet regulatory timelines.
To evaluate Services and schedule a gap analysis, visit our services or request a consultation via the contact us page.
References
- #StopRansomware Guide — Cybersecurity and Infrastructure Security Agency (CISA).
- Cyber hygiene helps organizations mitigate ransomware-related vulnerabilities — CISA.
- NIST IR 8374 Rev. 1 — National Cybersecurity Center of Excellence (NCCoE) / NIST.
- Microsoft incident response ransomware approach — Microsoft Learn.
- Ransomware guidance — FBI.